Python’s logging module provides a powerful framework for adding log statements to code vs. what might be done via using print() statements. It provides a system of logging levels similar to syslog-style levels that can be used to produce both on-screen runtime diagnostics as well as more detailed logs with full debug level insights into per module/submodule behavior.
Managing usage of logging() can be complicated, especially around the hierarchical nature of the log streams that it provides. I have developed a simple boto3 script that integrates logging to illustrate a basic usage that is easy to adopt and, in the end, not much more work than using print() statements. For detailed information on logging beyond what I present here, consult the excellent Python docs on the topic, as well as the links in the References section at the end of this post.
Logging Configuration
The setup for logging() that I am using involves two configuration files, logger_config.yaml and logger_config_debug.yaml. The difference between the two files has to do with the log levels used by the log handlers. By default, the example module deployVpc.py uses the logger_config setup. This config will produce no screen output by default except at the ERROR level and above. It produces a log file, however, that contains messages at the INFO level for the module and at the WARNING level for boto-specific calls.
Note: boto (including botocore) ships with some logging() active at the INFO level. While not as detailed as DEBUG, there’s enough busyness to that level of logging by boto that you will likely want to not see its messages except when troubleshooting or debugging your code. This is the approach I took with the current configuration, by opting to set custom logger definitions for boto and friends, so that the root logger will not by default display boto’s native log level messages.
Let’s take a look at the default logging configuration file I’ve put together, logger_config.yaml:
---
version: 1
disable_existing_loggers: False
formatters:
simple:
format: "%(asctime)s %(levelname)s %(module)s %(message)s"
fancy:
format: "%(asctime)s|%(levelname)s|%(module)s.%(funcName)s:%(lineno)-2s|%(message)s"
debug:
format: "%(asctime)s|%(levelname)s|%(pathname)s:%(funcName)s:%(lineno)-2s|%(message)s"
handlers:
console:
class: logging.StreamHandler
level: DEBUG
formatter: simple
stream: ext://sys.stdout
screen:
class: logging.StreamHandler
level: ERROR
formatter: fancy
stream: ext://sys.stdout
logfile:
class: logging.handlers.RotatingFileHandler
level: DEBUG
formatter: debug
filename: "/tmp/deployVpc.log"
maxBytes: 1000000
backupCount: 10
encoding: utf8
loggers:
boto:
level: WARNING
handlers: [logfile, screen]
propagate: no
boto3:
level: WARNING
handlers: [logfile, screen]
propagate: no
botocore:
level: WARNING
handlers: [logfile, screen]
propagate: no
deployVpc:
level: INFO
handlers: [logfile, screen]
propagate: no
__main__:
level: INFO
handlers: [logfile, screen]
propagate: no
root:
level: NOTSET
handlers: [console, logfile]
I chose to use YAML for the configuration file as it’s easier to parse, both visually and programmatically. By default, Python uses an INI file format for configuration, but both JSON and YAML are easily supported.
At the top of the file is some basic configuration information. Note the disable_existing_loggers setting. This allows us to avoid timing problems with module-level invocation of loggers. When logging per module/submodule, as those modules are imported early in your main script, they will not find the correct configuration information as it’s yet to be loaded. By setting disable_existing_loggers to False, we avoid that problem.
The remaining file consists of four sections:
- formatters
- handlers
- loggers
- root logger definition
Formatters
Formatters are used to define the log message string format. Here, I am using three different formatters:
- simple – very simple and brief
- fancy – more detail including timestamp for a helpful log entry
- debug – fancy with module pathname instead of module name, useful for boto messages
By default, I leave simple for the console handler (for root logger), use fancy for the screen handler, and debug for the logfile handler.
Handlers
Handlers are used to define at what level, in what format, and exactly where a particular log message should be generated. I’ve left console in its default configuration, but added a StreamHandler and a RotatingFileHandler. Python’s logging module supports multiple types of handlers including Syslog, SMTP, HTTP, and others. Very flexible and powerful!
- console – used by the root logger
- screen – log ERROR level and above using fancy formatting to the screen/stdout
- logfile – log DEBUG level messages and above using debug formatting to a file in /tmp that gets automatically rotated at 1MB and retention of 10 copies
Loggers
Loggers are referenced in your code whenever a message is generated. The configuration for a given logger is found in this section of the configuration file. In my case, I wanted a separate logger per module/function if necessary, so I’ve made entries at that level. I also include entries for boto and friends so I can adjust their default log levels so I don’t see their detailed information except when and where I want to (i.e., by logging at WARNING instead of INFO or DEBUG for normal operation). A logger entry also defines where log streams should end up. In this case, I send all streams to both my screen handler and my logfile handler.
I also don’t want custom loggers to propagate messages throughout the logging hierarchy (i.e., up to the root logger). So I’ve set propagate to “no”.
Implementing logging in code
Setup
I created a module called loggerSetup.py which is where I do the initialization for defining how logging() will be configured, via the configuration files:
#!/usr/bin/env python
"""Setup logging module for use"""
import os
import logging
import logging.config
import yaml
home = os.path.expanduser('~')
logger_config = home + "/git-repos/rcrelia/aws-mojo/boto3/loggerExample/logger_config.yaml"
logger_debug_config = home + "/git-repos/rcrelia/aws-mojo/boto3/loggerExample/logger_config_debug.yaml"
def configure(default_path=logger_config, default_level=logging.DEBUG, env_key='LOG_CFG'):
"""Setup logging configuration"""
path = default_path
value = os.getenv(env_key, None)
if value:
path = value
if os.path.exists(path):
with open(path, 'rt') as f:
config = yaml.safe_load(f.read())
logging.config.dictConfig(config)
else:
logging.basicConfig(level=default_level)
def configure_debug(default_path=logger_debug_config, default_level=logging.DEBUG, env_key='LOG_CFG'):
"""Setup logging configuration for debugging"""
path = default_path
value = os.getenv(env_key, None)
if value:
path = value
if os.path.exists(path):
with open(path, 'rt') as f:
config = yaml.safe_load(f.read())
logging.config.dictConfig(config)
else:
logging.basicConfig(level=default_level)
This module defines two functions: configure() and configure_debug(). This provides another way of running a non-default logging configuration without using the LOG_CFG environment variable (i.e., on a per-module basis). When you setup logging in your module like so:
loggerSetup.configure()
logger = logging.getLogger(__name__)
You would simply edit the first line to use .configure_debug() instead of .configure().
Usage
Usage is straightforward, simply do the following in each module you wish to use logging(). Refer to the deployVpc.py script for the full syntax and usage around these bits of code.
Note: deployVpc.py requires use of AWS API key access that is stored in a config profile (I used one called ‘aws-mojo’, change to your own favorite profile). It will create a VPC and Internet Gateway in your AWS account. But it will also, by default, remove those objects as well. Caveat emptor…
- Import the logging modules and loggerSetup module
import logging, logging.config, loggerSetup
- Activate the logging configuration and define your logger for the module
loggerSetup.configure()
logger = logging.getLogger(__name__)
Note: By using __name__ instead of a custom logger name, you can easily re-use this setup code in any module.
- Add a logger command to your code using the level of your choice:
logger.info('EC2 Session object created')
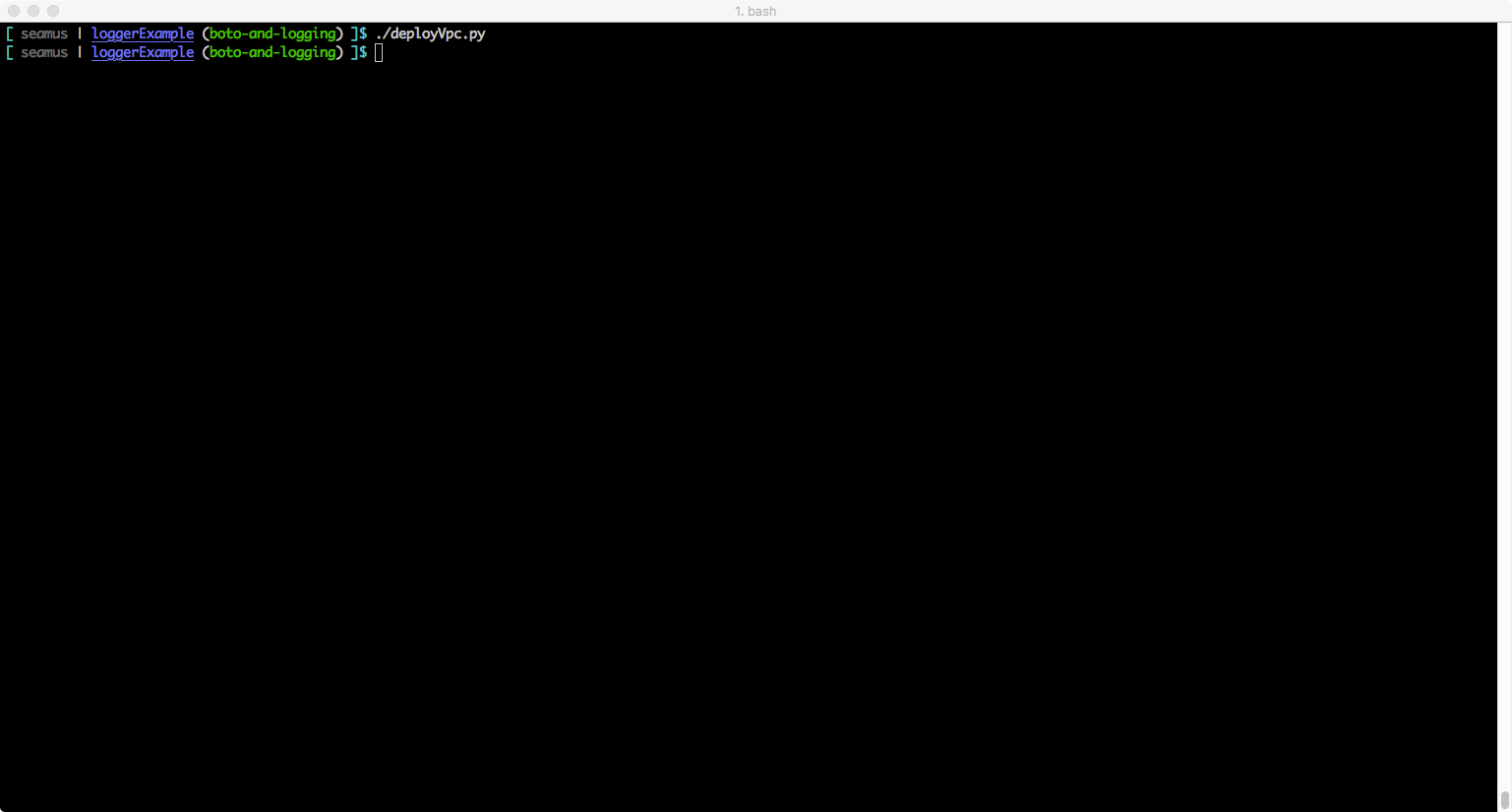
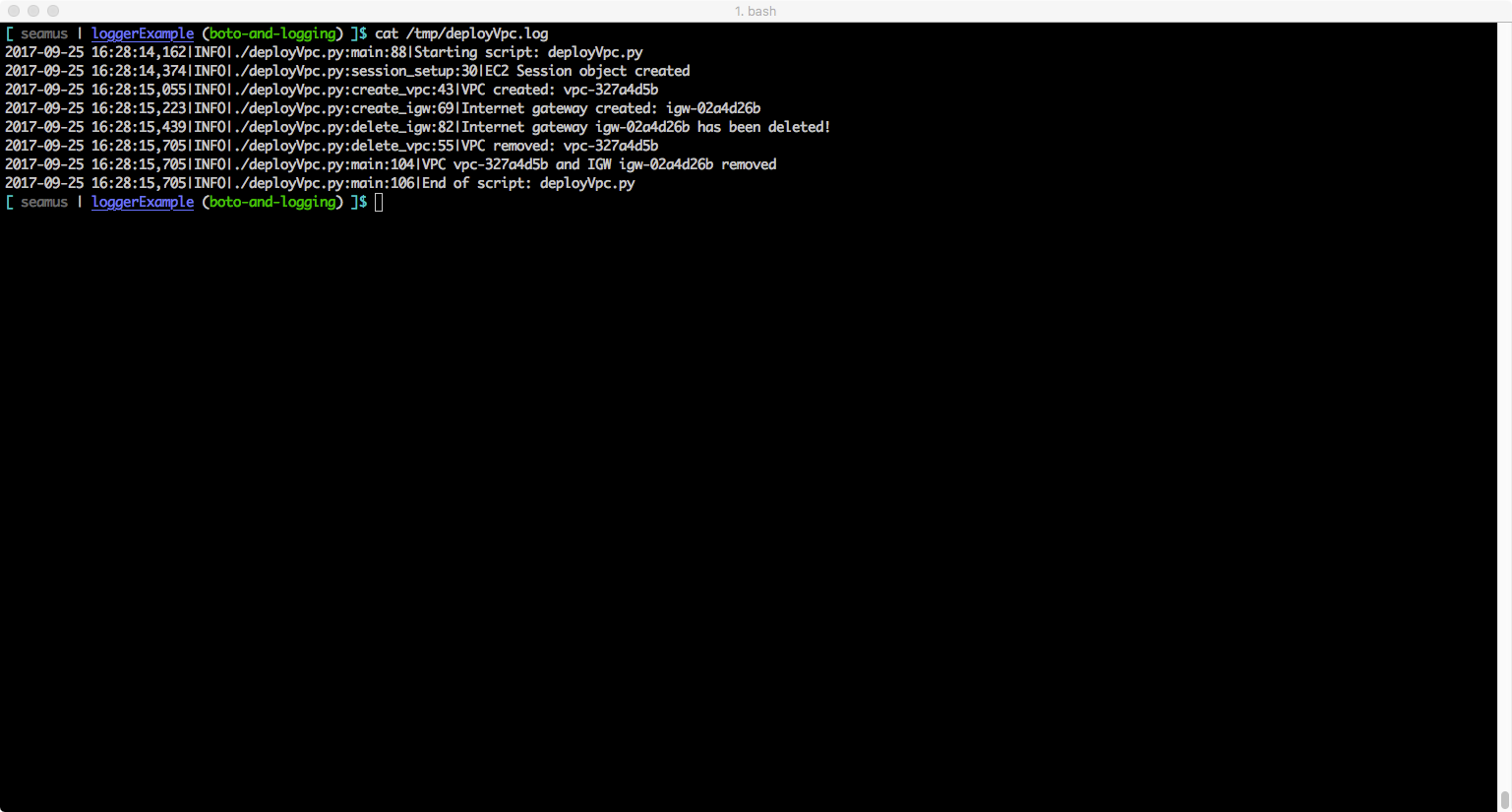
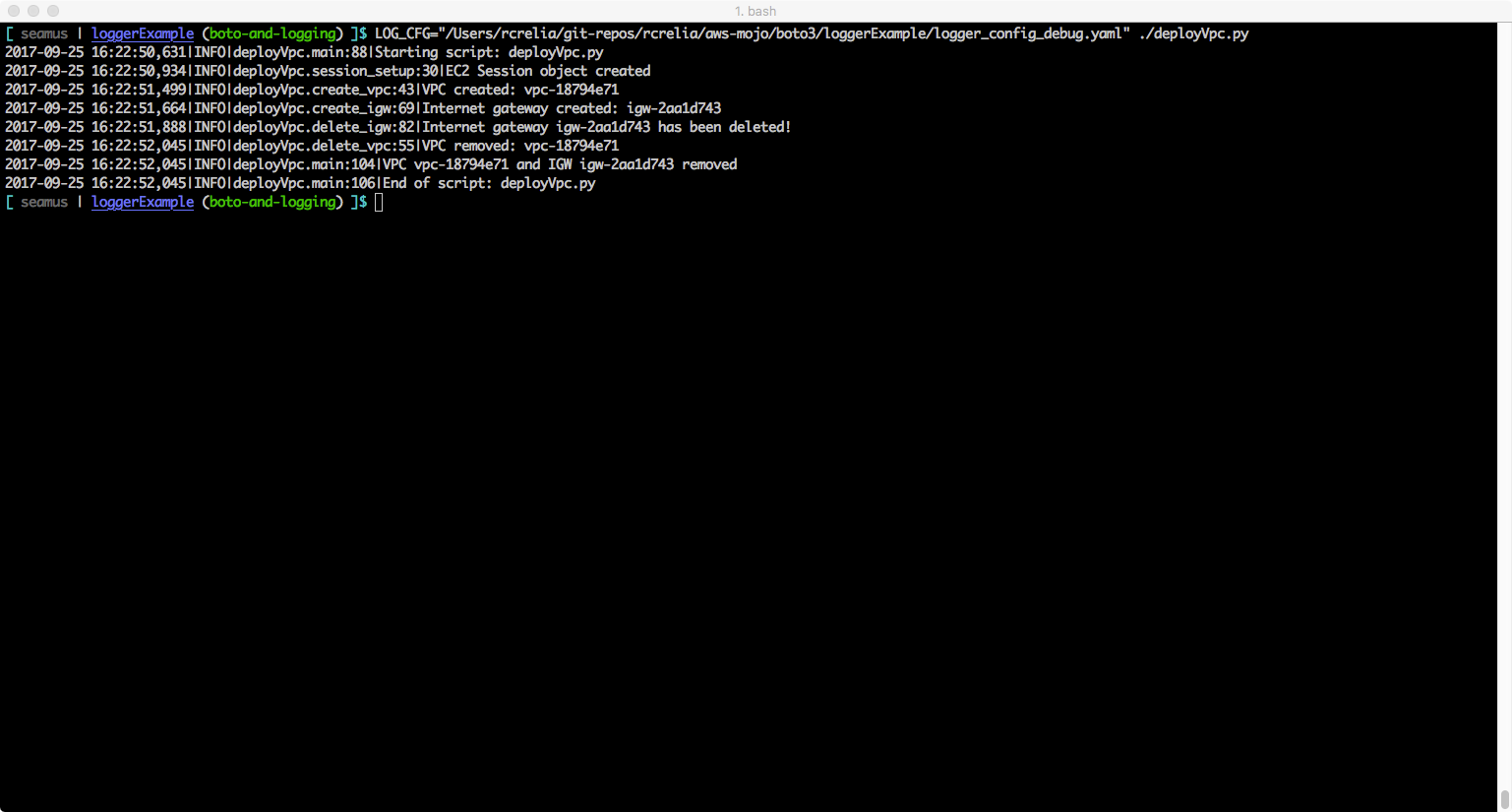
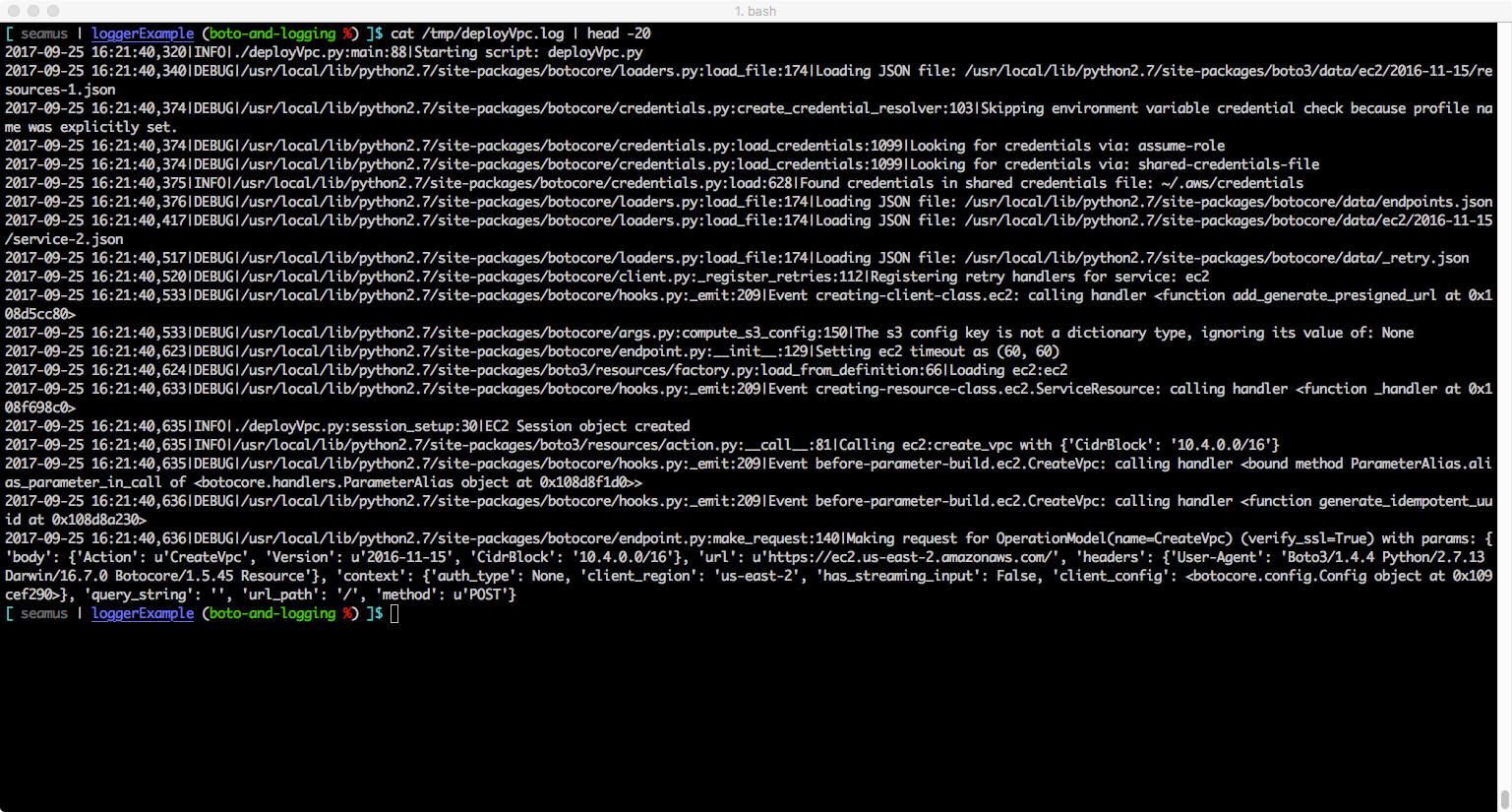
That’s all there is to it. Below are some screenshots that show the handler output (screen and logfile) for both the default and debug configurations. Hopefully this will encourage you to look at using Python’s logging() framework for your own projects.
The full source for all of the logging module configuration as well as sample boto script is available over on GitHub in my aws-mojo repository.
Screenshots
Example: Default configuration – output to screen handler (should be no output except ERROR and above)

Example: Default configuration – output to logfile handler (should be messages at INFO and above for your code and at WARNING and above for boto library code messaging)

Example: Debug configuration – output to screen handler (should be messages at INFO and above for your code and at WARNING)

Example: Debug configuration – output to logfile handler (should be messages at DEBUG and all levels for your code and boto library code messaging)

References
Continue reading →